
Context isolation in AI sub-agent architecture is a design approach that replaces monolithic prompting with modular, role-specific AI agents. By isolating context and intelligence, enterprises can build AI agents that are predictable, scalable, and governed by design. This article explains why enterprise AI systems fail with monolithic prompts—and how context-isolated sub-agents fix it.
The Old Reality: Monolithic Prompting
Early AI systems were built like a single, overloaded brain.
Every instruction, business rule, edge case, and policy was forced into one expanding prompt. On paper, this felt powerful. In practice, it created AI systems that were fragile, unpredictable, and difficult to control.
As teams kept adding requirements, the prompt kept growing:
- Context became noisy
- Instructions began to conflict
- Small changes had unintended side effects
- Output quality degraded over time
- Context became noisy
What started as a “smart assistant” slowly turned into a brittle system that only worked when everything went exactly right.
Behind the scenes, the problem wasn’t model capability.
It was monolithic prompting — a design pattern where all intelligence is forced to reason inside the same context, regardless of the decision being made.
Executive takeaway:
Bigger prompts don’t create smarter AI.
They create AI that’s harder to control, harder to scale, and harder to trust.
The First Attempt — Organizing the Chaos with RAG
As prompt complexity increased, our first instinct wasn’t architectural — it was operational.
In an attempt to reduce cognitive overload, we introduced Retrieval-Augmented Generation (RAG) with chunking strategies. The goal was simple: retrieve only the most relevant information instead of loading everything at once.
This approach improved retrieval efficiency.
But it didn’t change how the system thought.
All business logic — pricing rules, policies, workflows, and edge cases — still flowed into the same reasoning space. The prompt became cleaner and better organized, but it remained fundamentally monolithic.
RAG optimized what information was retrieved —
not how intelligence was structured.
That distinction is where the real problem revealed itself.
If this challenge feels familiar, we walk through how teams move beyond RAG-only systems in a short demo.
Context Isolation in AI Sub-Agent Architecture: From One Brain to Specialized Minds
Our Core Design Principle: Context Isolation
The breakthrough didn’t come from writing better prompts. It came from asking a more fundamental question:
Why are we forcing one AI to think about everything at once?
In real organizations, decisions aren’t made by a single overloaded mind. They’re made by specialists — each with a clear role, clear inputs, and clear boundaries.
AI systems deserve the same structure.
Instead of expecting one model to:
- Sell
- Support
- Onboard
- Explain policies
- Handle edge cases
—all within the same context, we redesigned the architecture to think before it responds.
That redesign is based on one principle:
Only load the context that is required for the decision at hand — and nothing else.
This is what we call Context Isolation.
Context isolation means:
- Intelligence is modular, not monolithic
- Instructions are scoped, not shared
- Each decision happens inside a controlled environment
Rather than one massive prompt, the system is composed of multiple focused AI sub-agents, each responsible for a specific type of outcome.
No agent sees more than it needs. No agent carries logic that doesn’t apply.
The result isn’t AI that sounds more complex. It’s AI that behaves more predictably.
This shift — from a single, overloaded brain to a set of specialized minds — is what makes scalable, enterprise-grade AI possible.
And it’s the foundation for everything that follows.
High‑Level System Flow (A Bird’s‑Eye View)
Once intelligence is modular, the system no longer reacts blindly. It follows a deliberate flow — where every stage has a single responsibility.
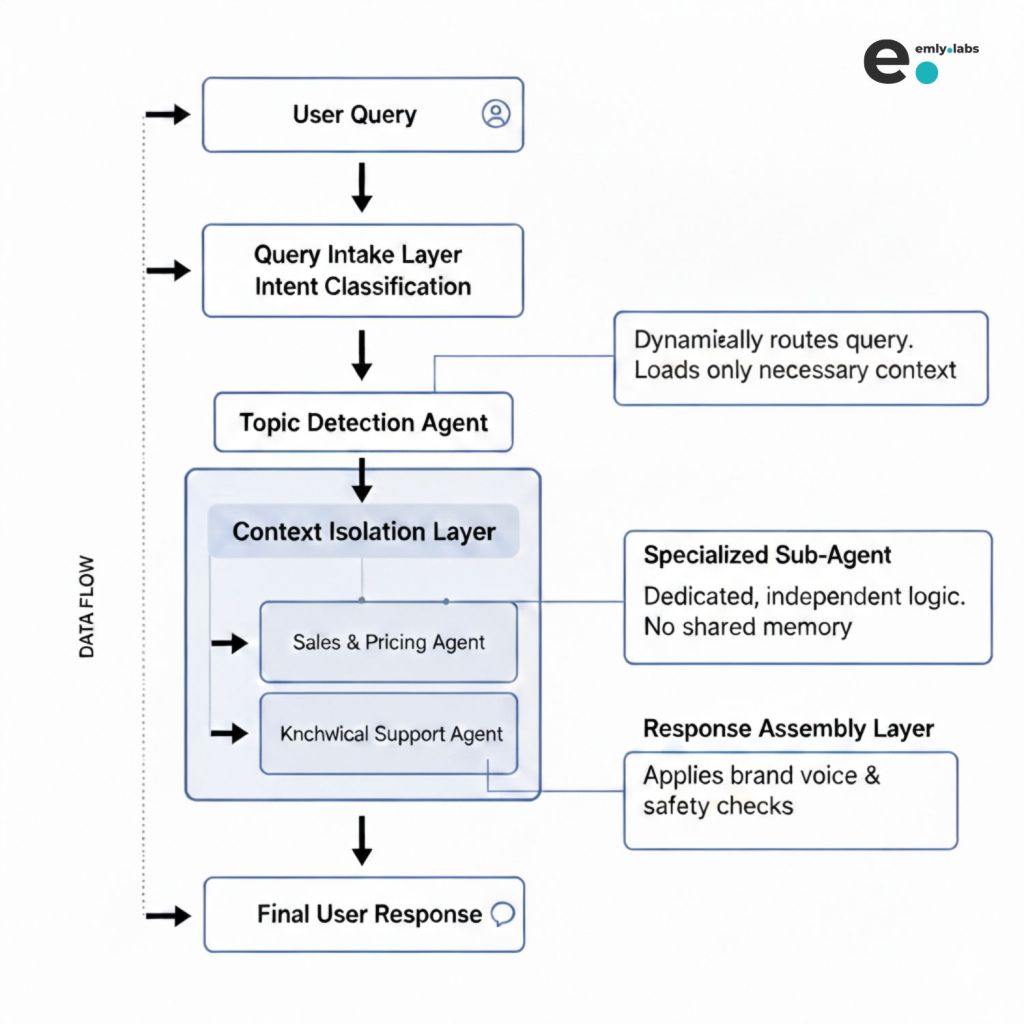
At a high level, this flow may look simple — and that’s intentional.
Each layer exists to reduce complexity, not add to it.
What leaders should notice
- Business logic is not loaded upfront
- Intelligence is introduced gradually, only when required
- No single layer is responsible for “thinking about everything”
The most important shift is this:
The architecture decides how to think before it decides what to say.
By separating intake, intent understanding, reasoning, and presentation, the AI remains controlled at every step.
There is no prompt explosion. There is no accidental context leakage. There is no ambiguity about which logic is active.
Each stage hands off a clean, minimal signal to the next.
This is what allows the overall system to stay fast, predictable, and enterprise‑safe — even as it scales across use cases.
In the next section, we’ll walk through this flow step by step, using a real user question to show exactly where intelligence is introduced — and where it is intentionally kept out.
Step‑by‑Step: What Happens When a User Asks a Question
This is where the architecture proves its value.
In practice, instead of reacting with a preloaded wall of instructions, the system introduces intelligence progressively — only when it’s needed.
Step 1: The User Query Enters the System

Example:
“Can you help me choose the right plan for my business?”
At this moment, something important doesn’t happen:
- No pricing rules are loaded
- No sales scripts are activated
- No assumptions are made about the user
The system simply receives the question.
This restraint is deliberate.
Why this matters:
Keeping the entry point lightweight prevents unnecessary context from influencing the outcome before intent is understood.
Step 2: Topic Detection Agent (Lightweight Intelligence)

The query is passed to a small, focused agent with a single responsibility:
Identify what the user is actually trying to do.
This agent:
- Uses minimal context
- Has no business rules
- Does not generate user-facing responses
Its output is internal and structured, for example:
- Intent: Pricing & Plan Recommendation
- Confidence: High
Why this matters:
This step prevents irrelevant logic from ever entering the system. Support instructions don’t mix with pricing. Onboarding flows don’t interfere with sales.
Step 3: Context Isolation (The Critical Moment)

At this stage, domain intelligence is introduced.
Instead of loading everything the business knows, this stage does something far more precise:
It loads only the context required for the detected intent.
In this case:
- Pricing rules
- Plan comparison logic
- Eligibility constraints
And nothing else.
No support workflows. No onboarding steps. No unrelated policies.
This is context isolation in action.
By narrowing the cognitive scope, the system creates a controlled environment where the response can be accurate, consistent, and explainable.
Step 4: AI Sub‑Agent Architecture (The Signature Design)
.

This is the structural decision that makes context isolation real.
Once intent is identified, the system does not “collaborate” across agents or blend instructions. It activates exactly one AI sub‑agent — the one designed for that outcome.
Visually, the architecture looks like this:

The Rules That Govern AI Sub‑Agents
Each AI sub‑agent operates under strict, non‑negotiable rules:
- Dedicated prompt: Purpose‑built for one type of decision
- Isolated context: Only the data and logic it requires
- Clear boundaries: What it can and cannot answer is predefined
AI Sub‑agents:
- Do not see each other’s instructions
- Do not inherit shared memory by default
- Do not improvise outside their domain
This is not a limitation. It is a control mechanism.
Why This Matters in Practice
From a business perspective, this design changes everything:
- Pricing logic never contaminates support responses
- Policy explanations never interfere with sales conversations
- Updates to one agent cannot silently break another
Adding a new capability doesn’t mean rewriting prompts. It means introducing a new AI sub‑agent with its own scope.
This is the difference between scaling prompts and scaling intelligence.
Want to see how this architecture works in a real system?
Book a demo to explore how Emly Labs applies context isolation and AI sub-agents in live sales workflows.
By enforcing isolation at the architectural level, the system remains understandable, testable, and safe — even as use cases multiply.
In the next section, we’ll step back from the structure and look at the outcome that matters most: how this design dramatically improves response quality.
Why This Dramatically Improves Output Quality
From an external perspective, the response may look simple.
But internally, everything has changed.
By isolating context and enforcing specialization, the system changes how decisions are made, not just how responses are phrased.
Precision Over Guesswork
Each AI sub-agent is designed to answer a narrow class of questions.
That focus eliminates ambiguity:
- No irrelevant assumptions
- No over-explaining
- No hedging caused by conflicting instructions
The agent answers what it was designed to answer — and nothing more.
Consistency at Scale
When logic is isolated, outcomes become repeatable.
The same question produces the same quality of response — regardless of when it’s asked, who asks it, or how many use cases exist in the system.
Pricing logic remains pricing logic. Support logic remains support logic.
There is no cross-contamination.
Maintainability Without Risk
In monolithic systems, small prompt changes often create invisible failures elsewhere.
With AI sub-agent architecture:
- Updating one agent does not affect others
- New policies are scoped to the right context
- Testing is targeted and predictable
This turns AI systems from fragile experiments into maintainable products.
Scalability Without Chaos
Growth no longer means adding more instructions to the same prompt.
It means expanding horizontally:
- New intent → new sub-agent
- New use case → new boundary
The system grows without losing clarity.
The outcome: AI that behaves the same way a strong organization does — through specialization, ownership, and clear lines of responsibility.
Cost Predictability as a System-Level Outcome
In monolithic prompting, every user query carries the full weight of the system — all rules, policies, and workflows are processed every time, driving token usage and cost up linearly as the system grows.
With context isolation, intelligence is introduced progressively: a lightweight routing step identifies intent, and only the minimal, relevant context is loaded for response generation.
While this approach involves multiple LLM calls, LLM pricing is driven by total tokens processed, not the number of calls. In practice, isolating context significantly reduces the overall token footprint — resulting in more predictable and cost-efficient AI systems.
In the next section, we’ll look at how responses are finalized — and why separating intelligence from presentation is the final layer of control.
Response Assembly (Controlled, Clean Output)
Once a AI sub-agent completes its task, the system makes a deliberate choice:
Intelligence does not speak directly to the user.
Instead, the output flows through a dedicated response assembly layer whose job is control, not creativity.
At a high level:

What This Layer Does
This layer is intentionally non-intelligent.
It:
- Applies brand voice and communication standards
- Enforces formatting and structural consistency
- Runs safety and compliance checks
- Ensures responses align with enterprise guidelines
- Applies brand voice and communication standards
What This Layer Never Does
Just as important — it does not:
- Reason or reinterpret decisions
- Inject new logic
- Alter the intent of the response
- Reason or reinterpret decisions
All thinking has already happened upstream.
Why This Separation Is Critical
Many AI systems fail at the last mile — where tone tweaks, safety filters, or formatting rules quietly distort meaning.
By separating decision-making from presentation, this architecture ensures:
- Business logic remains auditable and predictable
- Brand updates don’t require prompt rewrites
- Compliance rules evolve without touching intelligence
- Teams can safely iterate without unintended side effects
- Business logic remains auditable and predictable
The outcome:
Users receive clear, consistent responses — while the intelligence behind them remains controlled, auditable, and predictable.
What This Means for Enterprises
This architecture is not about making AI sound smarter.
It’s about making AI behave predictably inside real organizations.
For enterprises, the challenge with AI has never been fluency, It’s been control.
Predictability Over Surprise
When context is isolated and intelligence is scoped, outcomes become reliable.
- The same intent triggers the same logic
- Responses don’t drift over time
- Behavior doesn’t change because of unrelated updates
- The same intent triggers the same logic
This is what allows leaders to trust AI in customer-facing, revenue-critical workflows.
Governance Built In, Not Added Later
Because logic is modular:
- Decisions are traceable to a specific agent
- Changes are localized and reviewable
- Compliance and policy enforcement become systematic
- Decisions are traceable to a specific agent
AI stops being a black box and starts behaving like governed software.
Faster Evolution Without Fragility
Enterprise needs change constantly — pricing, policies, positioning, regulations.
With AI sub-agent architecture:
- Updates don’t ripple unpredictably across the system
- New use cases don’t require rewriting what already works
- Teams can move fast without breaking trust
- Updates don’t ripple unpredictably across the system
A Different Definition of Scale
Scale doesn’t come from bigger prompts or more context.
It comes from:
- Clear ownership of intelligence
- Well-defined boundaries
- Systems that grow horizontally, not chaotically
- Clear ownership of intelligence
In short:
This is how AI moves from impressive demos to dependable infrastructure.
What’s Next
Context isolation and AI sub-agent architecture are the foundation — not the finish line.
Once intelligence is modular and controlled, deeper design questions emerge:
- How do multiple AI sub-agents coordinate when a decision spans more than one domain?
- Where should memory live — and where should it be explicitly blocked?
- When is collaboration between agents useful, and when does it introduce risk?
- How do multiple AI sub-agents coordinate when a decision spans more than one domain?
These aren’t implementation details.
They’re governance decisions.
In the next pieces, we’ll unpack:
- Flow control across multiple agents
- Information boundaries and memory design
- The conditions under which agents should — or should not — collaborate
- Flow control across multiple agents
Each of these choices determines whether an AI system remains safe, predictable, and enterprise-ready as it scales.
One principle will remain constant:
We don’t scale prompts.
We scale intelligence — one context at a time.
Explore More on AI Architecture and Emerging Trends
Context isolation and sub-agent design are just the beginning of building robust, predictable, and scalable AI systems. If you’re interested in how these architectural principles play out in real applications and broader trends, check out some of our previous insights:
- How modern frameworks for AI chatbots and multi-agent workflows are shaping 2025-era systems.
- Why the best elective healthcare providers adopt hybrid AI + human support models.
- Practical use cases for AI agents in healthcare and diagnostics.
- Lessons from AI agents in finance and retail that extend beyond support systems.
- A deeper look at the biggest challenges with traditional AI chatbot models and how to fix them.
These resources will deepen your understanding of AI systems that are not just smart, but strategically scalable and business-ready.
See this architecture in action
Context isolation and AI sub-agent design aren’t just concepts — they’re how high-performing AI systems are built in practice.
If you’re exploring AI for sales, support, or customer engagement and want to see how a controlled, cost-efficient system works in real workflows, book a demo with our team.
We’ll walk through how modular AI decisions actually look — from intent detection to response generation.